
『生成AIグラビアをグラビアカメラマンが作るとどうなる?連載記事一覧』
Boston Dynamicsのヒューマノイドロボ「Atlas」引退、さよなら動画公開 「油圧式Atlasはゆっくり休む時間を迎えた」
API経由ながらStable Diffusion 3が利用可能に!
今年、2024年2月24日に次世代Stable Diffusion、Stable Diffusion 3が発表された。いろいろな特徴があるのだが、画像品質の向上はもちろんのこと、Stable Diffusion (XL) が苦手だった文字 (但し日本語などは除く) にも対応し、早く使いたかったものの、まだ一般が試せる状態ではなかった。
ところがつい先日の4月17日、Stability AI Developer PlatformのAPI経由で利用可能となったので、使ってみたのが今回の内容となる。
APIを使うにあたって必要なAPI Keyは、Stability AI にアカウントを作ると用意され、自動的に24クレジットが付加される。1枚作って消費するクレジットは以下の通り。
参考までにStable Diffusion XLだと0.2から0.6クレジット。初物なので仕方ないとは言え10倍前後の差がある。
いずれにしても25クレジットだと数枚生成すれば0になってしまい、この場合はチャージすることになるが、$10で1,000クレジット。まぁそんなに高いわけでもないので、切れたらチャージすればいいだろう。
問題は何のアプリで生成するか?一般的なAUTOMATIC1111は未対応、Pythonのプログラムを書けばいいのだが、それも面倒…っと思っていたところ、ComfyUIのカスタムNodeが出たので早速使用した
ComfyUIのカスタムノードでStable Diffusion 3を使う方法
ComfyUIのStable Diffusion 3対応カスタムNodeをComfyUIで動かす手順は以下の通り。
次にComfyUIでStable Diffusion 3のNodeを利用できるようにするには…。
これでOK。簡単だ!
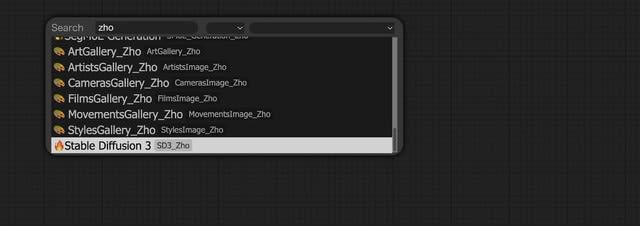
Nodeは何も無いところでダブルクリック、検索パネルを出して、zho(作者の名前)で検索すれば”Stable Diffusion 3”があるので、それを選択する。以下のようなNodeが出れば正解。
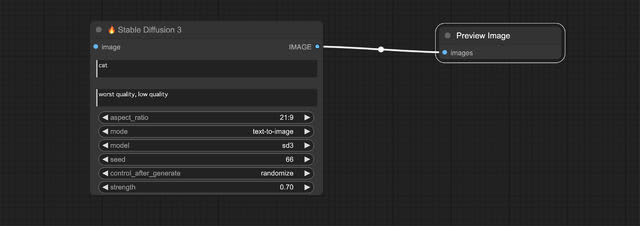
仕上げはこれだと生成した画像が見れないので、右にあるIMAGEからPreview Image (もしくはSave Image) Nodeを繋ぐ。これで準備完了だ。
早速生成!
この状態でPromptに「cat」、Negative Promptに「worst quality, low quality」が入っているのでそのまま生成したのが以下の猫の画像。
次に、「(best quality:1.2),photo of a japanese woman, 20 years old, (off shoulder sweater:1.2), short hair, standing」(画面キャプチャ)。
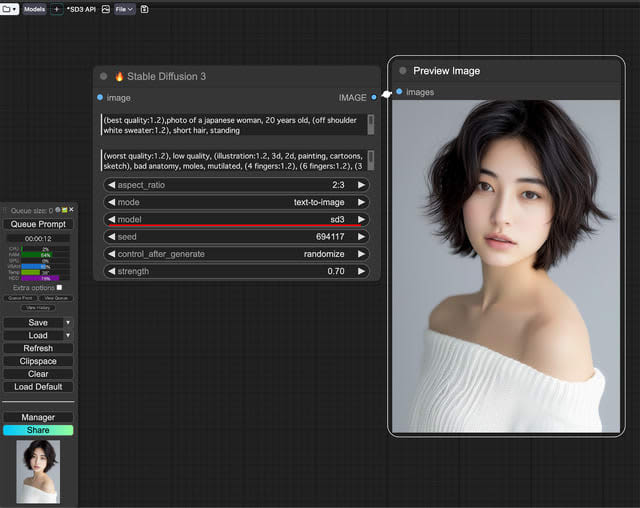
Nodeを見るとmodelをsd3とsd3 turboの切り替えができる。sd 3 turboにして同じPromptで作ったのが2となる。
また特徴として文字が描画出来るとあったので「photo of a japanese woman, 20 years old, standing, maid cosplay, at maid cafe, name is "Techno Edge"」としたところ、それっぽい場所にカフェ名のTechno Edgeと入った!
いずれも解像度は2:3で832x1,216px。これはStable Diffusion XLと同じだ。そう考えると、Stable Diffusion XLは当初、純正のModelだと人肌がツルツルでイマイチだったが、そこはクリアしているのが分かる。
今後、普通にHugging FaceやCivitaiにModelが掲載されれば、いろいろなリアル系やイラスト系のModelが出て面白そうだが、はたして一般家庭用最大VRAM容量の24GBで学習できるのだろうか? こればかりは実際ものが出てこないと分からない部分でもある。
さてAPIを使った場合の最大の弱点は、筆者が好んで出しているグラビア系=肌色過多は、APIのリターン時に”content_moderationエラー” (不適切な内容をモニタリングエラー) となるか、ご覧の様にボケた画像が出てくる。
この画像、左側と同じPromptでたった1枚得るのに6回ほどエラーもしくはボケた画像が出てきた。最近、LLMも含め、海外のこの手のサービス(システム)は、センシティブなものに過激なほど敏感。そのうち人がらみは何も出なくなるのでは!?(笑)。
今回締めのグラビア
本来ならStable Diffusion 3で扉とグラビアを出したいところだが、まだ、そこまでの絵が出ないのと、少し女性がからむと、結構な割合で、エラーかボケた画像。でもクレジットは減る…と、使えない状況なので今回は諦めた。ローカルで生成出来るようになったら再チャレンジしたい。
そこで、今回はまだ未完成?の筆者が撮影したグラビアを学習させた、自作リアル系Modelを使ってみた (扉とグラビアは別の試作Model) 。ご覧の様に、リアル系はリアル系でも (当たれば) 、あまり見かけない肌感になっててちょっと面白い逸品となっている。

話を戻すと、Stable Diffusion 3が出る前、2月13日にStable Cascadeが発表されている。どちらが本命なのだろうか!?今のところStable CascadeのModelはいくつか出ているものの、決定打的なものは未だ無い。さてどうなることやら…。
