
Stability AIからStable Diffusionの新しいバージョン「Stable Diffusion 3」がAPI限定で公開されました。アプリケーションに組み込んで特徴やコストなどを検証しました。
Boston Dynamicsのヒューマノイドロボ「Atlas」引退、さよなら動画公開 「油圧式Atlasはゆっくり休む時間を迎えた」
Stable Diffusion 3の概要
「Stable Diffusion 3(SD3)」は画像生成の代表的なプロダクトであるStable Diffusionの、SDXLに続く最新バージョンです。
基本的性能の向上
全体的に表現力が向上し、プロンプト(生成する画像の指示)に対するより高い忠実度や、複数の被写体が混在する表現の向上、高解像度での適切な生成が謳われています。

▲複雑で自然な文章による指示への忠実性(研究論文より)
合成キャプションを用いた学習や、3つのテキストエンコーダの組み合わせなどアーキテクチャを変更し、モデルサイズも8B(80億パラメータ)まで拡大。審美性・プロンプト忠実性・タイポグラフィの3つで取ったベンチマークでは、Midjourney v6やDALL-E 3など多くの競合を上回るとしています。
論文に掲載された例やSNSなどでのサンプルを見ると、たしかに複雑なプロンプトでより意図に沿った出力ができているようです。画像生成の普及初期に「呪文」などと呼ばれた特殊なプロンプトは不要になり、より自然な表現で指示できるようになっていることは、利用の広がりにつながる重要な発展です。SDXLなど以前のバージョンでもそうした傾向にありましたが、SD3では更に改善しています。LLMなど他の生成AIとの組み合わせて利用する上でも、生成したい表現と指示の互換性が高まるのはとても嬉しい点です。
文字表現の強化
SD3の大きな特徴として、タイポグラフィ、つまり文字の表現力向上が挙げられています。Stable Diffusionは従来文字を描くのがかなり苦手でした。単純な「Aという文字」という指示ですらまともに表現できないケースが大半でした。
テキストと画像に異なるモデルを用い、内部的にある種のマルチモーダルを採用したことで、SD3では文字表現が大幅に強化されました。論文には画像に文字表現が違和感なく溶け込む例が多数掲載されています。

▲文字を直接指示に含めた表現の例(研究論文より)
文字表現という性能への注力は、画像生成の用途を大きく広げる可能性に期待したものかもしれません。画像生成の商業利用を考えると
また文字の表現は、画像同様視覚的なものでありながら、写真やイラストとは異なる扱いがなければ正しく扱うのが難しい要素です。これは画像生成AIが多数の画像を解析してその表現を蓄えることと、文字として破綻しない表現を維持することの間に乖離があるためと考えています。文字は人間にとって単なる視覚表現を超えた、画像の範疇の外に正しさを持っています。
今回文字と画像に異なるモデルを採用し、それらを混ぜ合わせることでタイポグラフィが向上したことは、画像の範疇の外に正しさを持つ同様の視覚表現にも適用できるかもしれません。たとえば正確な線、完全な白ベタ、図面や楽譜、機械や建物などなど、記号や意味的な正しさが求められるものに、異なるモデルを内部的に統合することで改善が可能ならばと期待します。
SD3 APIの概要
Stable DiffusionはMidjourneyやDALLEなど他の画像生成サービスと違い、必要なデータをダウンロードしてローカルで実行したり、追加の学習を加えたりできる点が最大の強みです。しかし今回のSD3はまだダウンロード可能なデータは公開されておらず、Web経由で使える有料のAPIのみの公開です。
最近のStability AIの製品の多くは、商用利用に制限のある研究用ライセンスで公開されています。商用利用したい場合は月額有料制のメンバーシップに加入する必要があり、SD3も同じ仕組みで公開される予定がアナウンスされています。
なおローカル動作に必要なハードウェア性能ですが、最適化前の状態で、最大となる8BパラメータモデルがVRAM24GBで扱えることが確認されています。また、公開時にはより小さいパラメータのモデルを増やして3種が用意されます。
24GBは一般向けのGPUで最大のVRAM容量であり、個人的にはできれば16GBで8Bモデルが動作できる最適化を期待しています。
APIの利用価格
従来からSDXLなど旧来のモデルでも画像生成APIは提供されており、なかなか安価に利用できました。しかし今回のSD3では利用価格が大幅に値上げされています。
Stability AIのAPIはクレジット式で、1000クレジット10ドルから購入できます。1ドル150円で日本円換算すると、1クレジットあたり1.5円。SDXLの場合は基準価格が0.2~0.6クレジットだったので、1024x1024の画像が0.6円程度で生成できました。一方SD3は一気に値上がりして1枚の生成で6.5クレジット、つまり9.75円必要です。
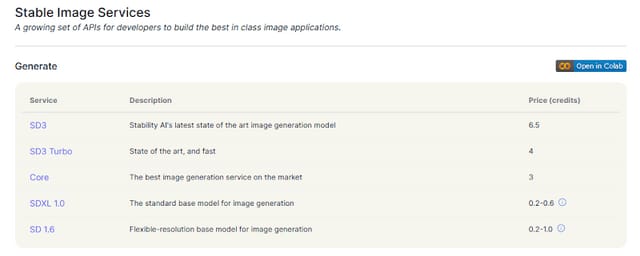
▲Stability AIの画像生成API利用価格表
15倍以上の値上げはかなり大きく、OpenAIのDALLE3 APIの基準価格が0.04ドル=6.2円弱ですから、それより更に上です。まだまだ計算負荷が大きくコスト高という理由もあるとは思いますが、モデルデータの公開というStable Diffusionの立ち位置を考えると、収益性のために割高な利用価格を設定するのは避けられないのかもしれません。
また今回からAPIの基盤がFireworks AIというAIモデルの実行環境を提供するサービスに変わっています。こうしたサービスを利用することで、利幅の分割高になっている可能性もあります。あまり価格が高いと、自分で実行環境を用意したり、Fireworks AIを使ったりを選択するユーザーが増えそうで、最適化や価格改定に期待したいです。
なおSD3にはSD3-Turboという派生モデルがあり、これもAPIで提供されています。SD3-Turboは過去にSD-Turboとして提供された高速版同様、生成の速さと品質のバランスが取れたモデルで、利用価格は4クレジット。恐らく演算時間の少なさからの値付けですが、SD3ほどの表現力やタイポグラフィ性能はないため、使い分けが必要そうです。
アプリケーションへの組み込み
私は今、Witchpotさんと一緒にGlimnoteというサービスを開発しています。このサービスは、テキスト生成や画像生成を組み合わせてゲームや物語の世界構築をサポートするもので、すでにSDXLのAPIを使った画像生成が組み込まれています。
▲Glimnoteでの画像生成(画面は開発中のもの)
今回はこのGlimnoteにSD3のAPIを組み込んで、いくつかの性能をテストしてみます。
APIの仕様変更
APIがFireworks AIから提供されることになったため、細かい仕様がいろいろと変わっています。
プログラミング上はリクエストのボディがapplication/jsonからmultipart/form-dataに変わったり、モデルの指定が同一のエントリーポイントで切り替えたり、概ね使いやすくなりました。また返される画像がbase64だけでなくPNGやJPEGも選択できるようになったため、実装の選択肢も増えました。
一方指定可能なパラメータは減っており、サイズは直接指定できずアスペクト比のみ、CFGスケールやステップ数もお任せとなっています。まだまだ実験に近い状態という印象のため、この辺りは最適化が進めば受け入れられるようになるかもしれません。
Glimnoteでの差し替えでは特に悩む点はありませんでした。むしろ多くのAPIに近いシンプルな実装で済むようになったためコンパクトになり、base64前提の既存のフローへの適用も問題ありません。SDXLなど既存のAPIを採用していないアプリケーションでも、かなり少ない工数で組み込めるでしょう。
生成のテスト
ツールに組み込んだ機能を使い、生成のテストや比較を行います。
同一条件のキャラクター表現
まずは全く同じ条件で、SDXLとSD3の出力を比較します。お題はポストアポカリプスもののゲームキャラクターで、プロンプトは次のもの。
Character: A middle-aged man with a scarred face, possessing a resilient intellect that does not lose hope even in the midst of despair. He is muscular and wears practical clothing, and carries a worn-out laptop as a hidden possession. Game: Post-apocalyptic. Aesthetic: Abstract watercolor paintings, dark, decay, and destruction.


▲SDXL(左)とSD3(右)の出力
同じような条件で試してみた共通の傾向として、SD3の方が緻密な描写が増え、よりリアリティの強い出力をするようです。「Abstract watercolor paintings」や「dark, decay」など画風の指示がより反映されます。総じて画質や表現力が向上しているのは実感できます。
SDXLで難しかった表現
従来適切な出力が難しかった表現は色々ありますが、個人的な課題から「街づくりゲームのアセット」を生成してみます。


▲SDXL(左)とSD3(右)の出力
プロンプトは共通で、次のとおり。
Buildings for city building game from isometric perspective. It looks like a real building with its beautiful texture and appropriate level of realism.
SDXLは直線の表現が苦手で、どこかしら歪み、特に建物のアセットではそれが目立っていました。SD3ではこの点も改善されており、かなり期待できます。いずれControlNetなど制御技術が出てくれば、ゲームアセットの生成に大きく寄与しそうです。
複数の被写体
SD3の売りのひとつである、複数の被写体の表現を確認します。

▲ドラゴンと少女の写実的な表現
これは冒頭にも掲載している画像で、ドラゴンに寄り添う少女という被写体を、写実的に表現したものです。私のベンチマークのひとつで、架空のドラゴンをどれだけ現実的に描けるかと、さらに寄り添う人物にも注文をつけるややこしい題です。
もっと無茶なプロンプトを試しましょう。

▲「不機嫌なサボテンの妖精。妖精の上にはふかふかの枕。枕の上には老人が座る。老人の手のひらにはりんごのキャラクターが乗っている。」の出力結果
「不機嫌」が「老人」にかかったり、サボテンの妖精と枕の位置が正しくありませんが、従来だともっとプロンプトの要素がごちゃ混ぜになっていました。たとえばSDXLだとこうなります。

確かにプロンプトの忠実性、そして複数被写体の表現は向上しているようです。
タイポグラフィ
目玉機能のタイポグラフィも試します。

「Q」を象ったアクセサリーはかなりきれいに出ました。元々SDは宝石や貴金属の表現に強いので、文字との組み合わせも上手くいくようです。

こちらはジオラマ写真でミニチュアのフィギュアたちに「HAPPY」というオブジェを囲んでほしかったんですが、HAPYYとありがちなスペルミスに。

「42」という文字を漫画風に。文字は申し分ないですし、思ったより漫画に強くなっているようです。漫画としては、さまざまな表現が混ざりすぎてまだまだ奇妙ですが、チューニング次第で実用が進みそうです。スクリーントーンっぽいモアレまで学習していたりと、漫画はかなりデータセットに増えたのかもしれません。

自身の証明としてIDなどの文字を持った写真を使う場合がありますが、無意味になっていきそうです。この画像はわざと奇妙なものを選びましたが、より自然なものは現時点でも可能です。
ロゴ・シンボルマーク
SD3のタイポグラフィの強化が発表されて期待したのが、文字を使ったロゴやシンボルマークの表現です。「Glimnote」という文字列で試してみましょう。




予想通り良い出力が得られました。当然そのまま使えるわけではないですが、プロトタイプを大量に出すなど、文字と多様な表現の組み合わせをかなり自由に扱えることで、ロゴ作りにも大きく影響しそうです。DALL-E 3もある程度は文字を扱えますが、より正確で自然なSD3のインパクトは大きいです。
まとめ
現時点ではAPIのみの公開で、しかも割高なため、誰もが使える状況ではありません。しかしその表現力は素晴らしく、写実から文字まで幅広い。アニメ絵的なイラストに関心が薄いため、そうした用途ではまた異なる評価かもしれませんが、画像生成の次世代として着実さを実感できました。
価格を考えるとサービスに採用できるかは悩ましいところで、ローカル実行含め、最適化が進み解消されるのを期待しています。
関連リンク
生成AIグラビアをグラビアカメラマンが作るとどうなる? 第22回:Stable Diffusion 3リリース。ComfyUIを使いAPI経由で生成(西川和久)
